Seo Letter 120 * Content Keywords, Sitemaps, Segurança, Machine Learning
A black friday passou, as equipes de desenvolvimento e tecnologia sobreviveram e os bons resultados para o e-commerce e para os usuários foram surpreendentes.
Se por um lado se vendeu muito, por outro tivemos menos reclamações e usuários muito mais prevenidos para evitar problemas… talvez a única grande ressalva foi a bola fora da Adidas, shame on you adidas!
E se dezembro as temperaturas estão aumentando, no mundo da otimização o caldo também está fervendo e como de costume, sem mais delongas, vamos as novidades mais impactantes e fresquinhas do segmento de SEO.
RIP Palavras-chave do conteúdo
Alguns nem repararam mas o Google removeu o relatório “Palavras -Chave do Conteúdo” do Search Console que era um relatório criado ainda nos tempos de webmaster tools… sinto que estou ficando velho (mas não desatualizado ehehe).
Com o advento do Search Analytics e da opção de buscar e renderizar como o Google, esse relatório perdeu um pouco a utilidade e segundo o próprio Google também deixava os usuários um pouco confusos.
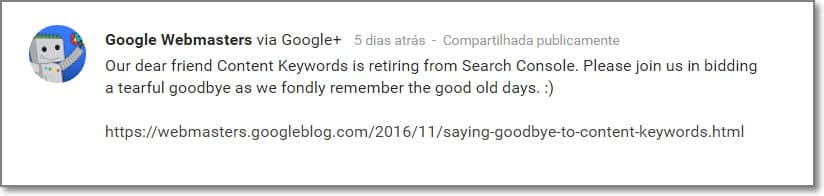
Pessoalmente eu gostava desse report porque ele conseguia me dar alguns insights rápidos em análises de contas novas, mas não adianta chorar pelo leite derramado, então que descanse em paz “Content Keywords” até porque já ajudou bastante eheheh.
Google Bing acabam com o regime dos Sitemaps
Google e Bing anunciaram em conjunto que o tamanho máximo para que aceitassem um sitemap passou dos míseros 10MB para 50MB.
Na prática dificilmente vemos Sitemaps com mais de 10MB, isso ocorre em poucas situações que Sitemaps tem urls longos assim como diversos atributos como imagens destacadas no xml e linguagens alternativas por exemplo.
Esse aumento de tamanho talvez seja um prenuncio do que pode estar por vir, talvez os mecanismos de pesquisas estejam se preparando para obter mais informações do Sitemap e por isso sempre é importante seguir o padrão e sempre mante-lo estruturado e livre de erros.
Só para frisar, muito embora o tamanho passou de 10MB para 50MB a quantidade de urls que pode ser enviada por Sitemap ainda é a mesma: 50 mil urls por Sitemap.
Noindex e Canonical não reduzem budget de rastreamento
Muito embora eu já tenha falado diversas vezes que noindex e Canonical não economizam o budget de rastreamento dos robôs de busca, sempre é bom ouvir a confirmação oficial de alguém no Google.
Em sua resposta, meu xará John deixa claro que provavelmente não ou não muito, então fica um pouco aberto se talvez economize um pouquinho ehehe.. de toda forma pelo contexto podemos considerar que praticamentenão economiza.
É importante lembrar que muito embora não se economize o orçamento de rastreamento com noindex e canonical, você ainda deve usa-los conforme as práticas recomendadas.
Se desejar reconomizar o budget de rastreamento a melhor maneira é bloquear direto no robots.txt mas sempre é necessário avaliar o impacto disso, uma vez que quando bloqueado o googlebot não vai ler essa(s) página(s) e não poderá descobrir outras ou diluir pagerank.
No final é necessário equalizar corretamente a utilização do robots.txt, noindex e canonical assim como um equilibrista de monociclo com pratinhos chineses ehehe.
probably not (or not much). we have to pick a canonical & have to crawl the dups to see that they're dups anyway.
— 🍌 John 🍌 (@JohnMu) November 30, 2016
Google ignora atributo lang por completo
John Mueller confirmou que o Google ignora por completo o atributo html lang (de language).
O mais interessante é o motivo que alegado para que o Google não o use:
We’ve found that this language markup is something that is almost always wrong. So we tend to ignore that.
Em outras palavras, isso significa que agora mais do que nunca se você tem um site exibido em diversos países será necessário utilizar as práticas recomendadas de Seo Internacional. O Google usa os atributos rel=”alternate” hreflang=”x” para entender o idioma correto ou o URL regional nos resultados de pesquisa.
Ficou na dúvida? Então confira no vídeo abaixo Jaos 55 minutos e 54 segundos quando Mueller confirma esse ponto.
Machine learning a todo vapor
Um artigo da Wired explica como o Google está usando machine learning para aprender e exibir feature snippets nos resultados, em outras palavras, o Google está ficando melhor a cada dia em ler, entender e extrair partes específicas de texto que possam responder de maneira objetiva a alguma pesquisa.
Enquanto só estamos falando de features snippets está tudo bem mas imagine se o Google começar a usar o funk fenomenal machine learning para começar a gerar automaticamente seus títulos e descrições na serp ein? Se isso acontecer uma grande parte do trabalho de otimização dos analistas de seo foi pro bro buraco rs.
Talvez não tenhamos entendido por completo a revolução que o machine learning e a inteligencia artificial possam causar mas pelo que ouvi no podcast de Gary Illyes (abaixo), acho que pode ser uma grande revolução.
https://soundcloud.com/marketingland/marketing-land-live-31
Gary citou que ambos (machine learning e a inteligencia artificial) podem ser usados para criar novos sinais de posicionamento. Aparentemente além de reconhecer novos sinais que podem ser usados, também poderemos ter melhoria dos sinais inclusive com agregação de fatores, por exemplo: combinar o pagerank com o panda; como disse Gary.
Nova política para safe browsing violations
O Google anunciou que está reforçando sua política de safe browsing violations, isso significa que se você for reincidente, não vai poder conseguir pedir reconsideração com menos de 30 dias.
Talvez seja muito forte mas acho que no final vai obrigar os webmasters, principalmente os que já tiveram seu site invadido, a reforçar a segurança, já que uma segunda ou terceira invasão pode deixar seu site com esse avisa vermelho GIGANTE durante 30 dias, o que provavelmente vai derrubar suas visitas, conversões e receitas.

Insanidade é continuar fazendo sempre a mesma coisa e esperar resultados diferentes. Albert Einstein
Newsletter
Inscreva-se para receber conteúdo incrível em sua caixa de entrada e ser avisado sobre lives e novos conteúdos!
Cursos do Martin
Veja os cursos disponibilizados
Mais da Agência SEO Martin
Conheça os principais serviços oferecidos pela Agência SEO Martin.



